Machine learning (ML) and artificial intelligence (AI) are transforming the way software is written and, more importantly, what software is capable of. Developers are accustomed to writing code that solves problems algorithmically. It’s not difficult to write an app that hashes a password or queries a database. It’s another proposition altogether to write code that examines a photo and determines whether it contains a cat or a dog. Such tasks can’t be accomplished algorithmically. You can try, but the minute you get it working, I’ll send you a cat or dog picture that breaks the algorithm.
Machine learning excels at solving problems that aren’t easily solved using algorithms. I first became interested about 10 years ago when my credit card company called me and asked if I had purchased a plane ticket in Brazil. I said no. They said, “no problem, we’ll deny the charge.” It happened a few more times, and each time it wasn’t hard to imagine why they suspected fraud because I was thousands of miles from where the transaction took place. But one day they called and asked if I had purchased a $700 necklace at a jewelry store just two miles away. I had not. But I was curious. How did they know it wasn’t me?
It turned out that they run every transaction through a sophisticated ML model that is incredibly accurate at detecting fraud. That moment changed my life. It is a splendid example of how ML and AI are making the world a better place. Moreover, understanding how ML could look at millions of credit-card transactions in real-time and pick out the bad ones while allowing legitimate charges to go through became a mountain that I had to climb.
In a series of blog posts, I plan to introduce ML and AI in a manner that speaks to engineers and software developers. The goal isn’t to build data scientists or devise the next great neural network architecture. The goal is to introduce these world-changing technologies in a practical way that enables software developers to use them to solve business problems, and to build an intuitive understanding of how ML and AI work. Most courses on ML and AI contain lots of scary-looking equations. I’ll throw an occasional equation at you, but for the most part, my introduction to ML and AI will be math-free. And it will be liberally sprinkled with examples and illustrations from the Machine Learning and AI for Software Developers course that I teach at companies and research institutions worldwide.
What is Machine Learning?
At a high level, machine learning is a means for finding patterns in numbers and exploiting those patterns to make predictions. Train a model with thousands (or millions) of xs and ys, and let it learn from the data so that given a new x, it can predict what y will be. Learning is the process by which ML finds patterns that can be used to predict future outputs, and it’s where the “learning” in “machine learning” comes from.
As an example, consider the table of 1s and 0s below. It’s relatively simple for a person to examine this dataset and determine what the number in the fourth column should be by examining the numbers in the first three columns. In a given row, if the first three columns contain more 0s than 1s, then the fourth column – what data scientists refer to as the label column, which contains answers or outcomes – contains a 0. If, on the other hand, the first three columns contain more 1s than 0s, then the answer is 1. Therefore, the red box in this example should contain a 1.

It’s not hard to examine a small dataset like this one and devise a set of rules for predicting labels. If all datasets were this simple, we wouldn’t need machine learning. But real-world datasets are much larger and more complex. What if the dataset contained millions of rows and thousands of columns, which, as it happens, is common in machine learning? For that matter, what if the dataset looked like this?

It’s difficult for any human to examine this dataset and come up with a set of rules for predicting whether the red box should contain a 0 or a 1. (And no, it’s not as simple as counting 1s and 0s.) Just imagine how much more difficult it would be if the dataset really did have millions of rows and thousands of columns.
That’s what machine learning is all about: finding patterns in massive datasets of numbers. It doesn’t matter whether there are 100 rows or 1,000,000 rows. In many cases, more is better, because 100 rows might not provide enough samples for patterns to be discerned.
It isn’t an oversimplification to say that machine learning solves problems by finding patterns in sets of numbers. Most any problem can be reduced to a set of numbers. For example, one of the common applications for ML today is sentiment analysis: looking at a document, a review on a Web site, or an e-mail and assigning it a 0 for negative sentiment (for example, “The food was decent but the service was terrible.”) or a 1 for positive sentiment (“Excellent food and service. Can’t wait to visit again!”) – or better yet, using the probability that the label is a 1 as a sentiment score. A very negative review might score a 0.1, while a very positive review might score 0.9, as in there’s a 90% chance that this is a positive review. Real companies use sentiment-analysis models to quantify sentiment in tweets and reviews and get a heads-up if sentiment turns negative.
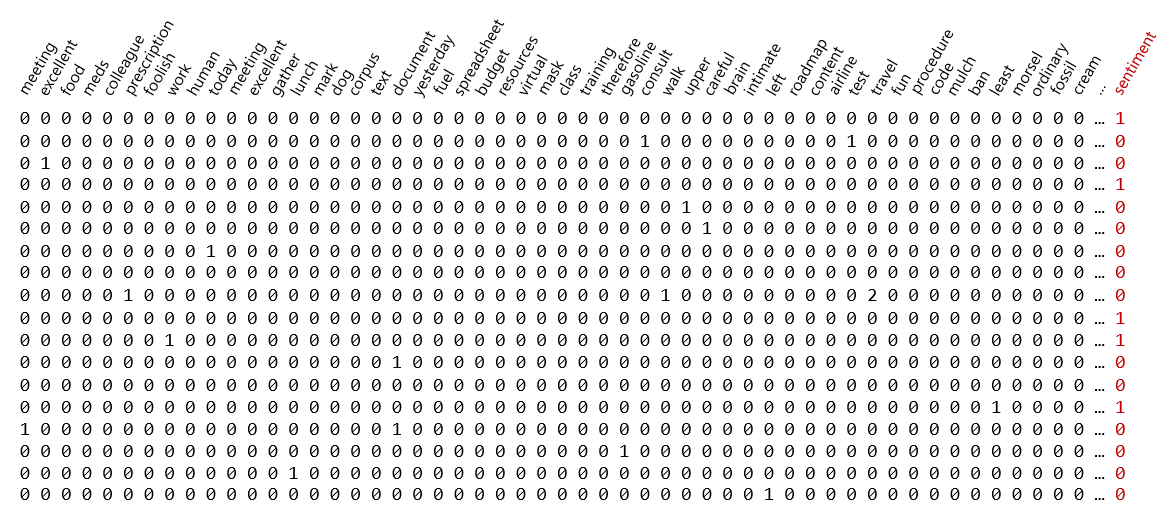
Sentiment-analysis models, spam filters, and other models that classify text are built around datasets like the one pictured below, in which there is one row for every comment or e-mail and one column for every word in the corpus of text (all the words in the dataset). A typical dataset like this one might contain millions of rows and 20,000 or more columns. Each row contains a 0 for negative sentiment in the label column, or a 1 for positive sentiment. Within each row are word counts – the number of times a given word appears in an individual comment or e-mail. The dataset is sparse, meaning it is mostly 0s with an occasional non-zero number sprinkled in. But machine learning doesn’t care. If there are patterns that can be exploited to determine whether the next comment or e-mail expresses positive or negative sentiment, it will find them. It is models like these that allow modern spam filters to achieve an astonishing degree of accuracy. Moreover, these models grow smarter over time as they are trained with more and more e-mails.
Sentiment analysis is an example of a text-classification task: look at a piece of text and classify it as positive or negative. Machine learning has proven adept at image classification as well. A simple example of image classification is looking at photos of cats and dogs and classifying each one as a cat picture (0) or a dog picture (1). Real-world uses for image classification include flagging defective parts coming off an assembly line, identifying objects in the crosswalk in front of a self-driving car, and facial recognition.
Image-classification models are trained with datasets like the one below, in which each row represents an image and the columns hold pixel values. A dataset with 1,000,000 images that are 200 pixels wide and 200 pixels high contains 1,000,000 rows and 40,000 columns. That’s 40 billion numbers in all, or 120,000,000,000 if the images are color rather than grayscale. The label column contains a number representing the class or category to which the corresponding image belongs – in this case, the person whose face appears in the picture: 0 for Gerhard Schroeder, 1 for George W. Bush, and so on.

The facial images above come from a famous public dataset called the Labeled Faces in the Wild dataset, or LFW for short. It is one of countless labeled datasets that are published in various places for public consumption. Machine learning isn’t hard when you have labeled datasets to work with – datasets that someone else (often grad students) have laboriously spent hours labeling with 1s and 0s. In the real world, data scientists sometimes spend the bulk of their time generating these datasets. One of the more popular repositories for public datasets is Kaggle.com, which makes lots of interesting datasets available and holds competitions allowing budding ML practitioners to test their skills.
What is the Relationship Between ML and AI?
The terms machine learning and artificial intelligence are used almost interchangeably today, but in fact, each term has a specific meaning as illustrated below.
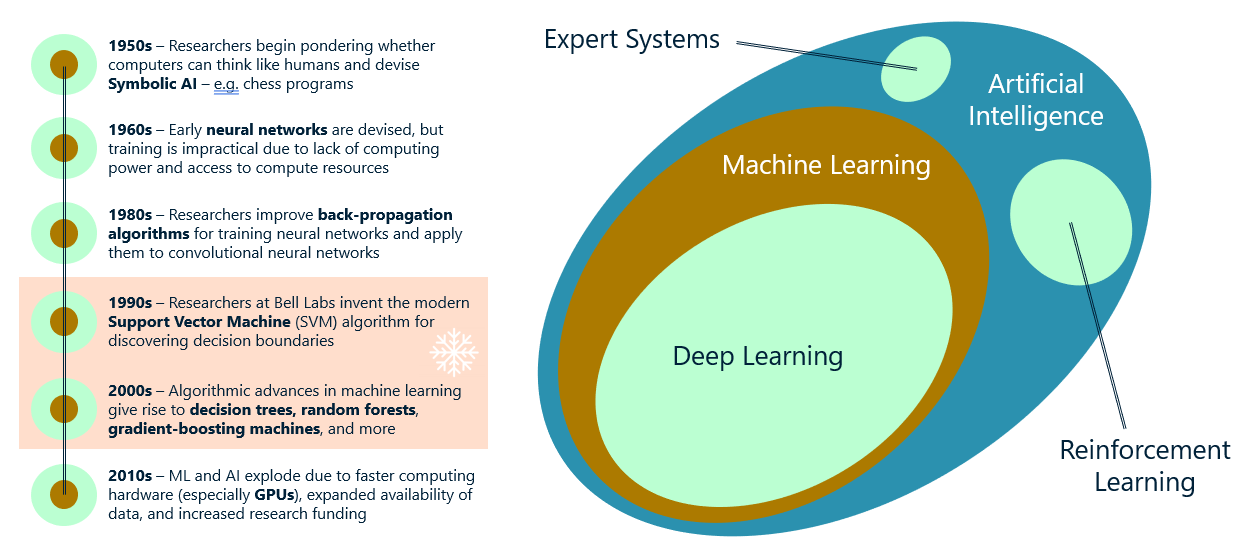
Technically speaking, machine learning is a subset of AI, which encompasses not only machine-learning models, but other types of models such as expert systems (systems that make decisions based on rules that you define) and reinforcement-learning systems. An example of the latter is AlphaGo, which was the first computer program to beat a professional human Go player. It trains on games that have already been played and learns strategies for winning itself.
As a practical matter, what most people refer to as AI today is in fact deep learning, which is a subset of machine learning. Deep learning is machine learning performed with neural networks. (There are a few examples of deep learning that don’t involve neural networks, but the overwhelming majority of deep learning is accomplished with neural networks.) Thus, we can divide ML models into traditional models that use statistical methods to find patterns in data, and deep-learning models that use neural networks to do the same. Don’t sweat it if you don’t know much about neural networks. I’ll cover them in later posts, but for the moment, it’s useful to build a foundation by learning about traditional ML models that rely on statistical methods such as linear regression, decision trees, and support vectors.
The timeline on the left side of the diagram reveals a bit about why ML and AI have become so popular in recent years. AI was a big deal in the 1980s, but excitement waned, and for decades – up until 2010 or so – it rarely made the news. Then a strange thing happened. Thanks to the availability of GPUs from companies such as NVIDIA, researchers finally had the horsepower they needed to train advanced neural networks. This led to advancements in the state of the art, which led to renewed excitement, which led to additional funding, which led to more advancements, and suddenly AI was a thing again. Neural networks have been around (at least in theory) since the 1950s, but researchers lacked the compute power to train advanced networks. Today, anyone can buy a GPU or spin up a GPU cluster in the cloud. AI is advancing now more rapidly now than ever before. And with it comes the ability to do things in software that we couldn’t have dreamed of just a few short years ago.
Supervised vs. Unsupervised Learning
Most ML models fall into one of two broad categories: supervised-learning models and unsupervised-learning models. The purpose of supervised-learning models is to make predictions. We train them with labeled data so they can take future inputs and predict what the labels will be. Most of the ML models in use today are supervised-learning models. These are sometimes referred to as predictive models because they are trained to make predictions. A great example is the model that the U.S. Postal Service uses to turn hand-written zip codes into digits that a computer can recognize in order to automatically sort the mail. Another example is the model that your credit-card company uses to authorize purchases.
Unsupervised-learning models, by contrast, don’t make predictions. Their purpose is to provide insights into existing data – even data that lacks labels. A great example of unsupervised learning is inspecting records regarding products purchased from your company and the customers who purchased them to determine which customers might be most interested in a new product you are launching and build a marketing campaign that targets those customers.
In my next post, I’ll introduce unsupervised learning and present some code samples demonstrating a powerful technique called k-means clustering.