While writing Chapter 14 of my book, Designing Silverlight Business Applications: Best Practices for Using Silverlight Effectively in the Enterprise (Microsoft .NET Development Series)
All of these solutions use the Entity Framework for data access. How that data access is projected to the client is illustrated bythree different patterns: OData (the straight services, not the checkbox on the WCF RIA Services tab), WCF RIA Services, and using the MVVM pattern. To simplify the examples I’m only focused on reads here. Writes do add a layer of complexity and change tracking, but I argue that the problem to solve there is not how to manage a large data set because anything the user actually interacts with is going to be a smaller order of magnitude.
If you are looking to upgrade your existing Silverlight application, our free whitepaper covers common approaches we’ve encountered to ensure you can still handle those large data sets using modern technology stacks.
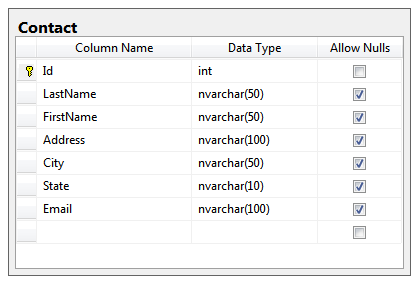
It’s extremely easy to expose an OData end point from a .NET web application. You can simply add a new WCF Data Service and then define what it has access to. In this example I have a Contact table that looks like this:
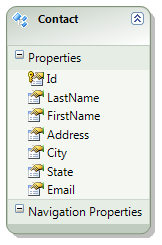
After generating the data model, the Entity Framework provides this in my ContactModel space:
The underlying context that was generated is called ContactEntities so for my OData service I can simply point to the underlying context and specify which collections are available and what access rights the client should have:
public class ContactOData : DataService<ContactsEntities>
{
public static void InitializeService(DataServiceConfiguration config)
{
config.SetEntitySetAccessRule("Contacts", EntitySetRights.AllRead);
config.SetEntitySetPageSize("Contacts", 20);
config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V2;
}
}
Note I’ve specified a page size of 20 records so that the service doesn’t return all 1,000,000 records at once. When I hit the service endpoint, I get this:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<service
xml_base="http://localhost:59389/ContactOData.svc/"
xmlns_atom="http://www.w3.org/2005/Atom"
xmlns_app="http://www.w3.org/2007/app"
>
<workspace>
<atom:title>Default</atom:title>
<collection href="Contacts">
<atom:title>Contacts</atom:title>
</collection>
</workspace>
</service>
This is all a client needs to begin navigating entities as the location of the first collection, Contacts, is clearly specified. We can now navigate to the contacts and receive something like this:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<feed
xml_base="http://localhost:59389/ContactOData.svc/"
xmlns_d="http://schemas.microsoft.com/ado/2007/08/dataservices"
xmlns_m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata"
>
<title type="text">Contacts</title>
<id>http://localhost:59389/ContactOData.svc/Contacts</id>
<updated>2011-11-20T16:24:05Z</updated>
<link rel="self" title="Contacts" href="Contacts" />
<entry>
<id>http://localhost:59389/ContactOData.svc/Contacts(1)</id>
<title type="text"></title>
<updated>2011-11-20T16:24:05Z</updated>
<author>
<name />
</author>
<link rel="edit" title="Contact" href="Contacts(1)" />
<category term="ContactsModel.Contact" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" />
<content type="application/xml">
<m:properties>
<d:Id m_type="Edm.Int32">1</d:Id>
<d:LastName>Alford</d:LastName>
<d:FirstName>Lucius</d:FirstName>
<d:Address>Ap #363-9702 Sit Rd.</d:Address>
<d:City>Jordan Valley</d:City>
<d:State>CO</d:State>
<d:Email>mi.eleifend.egestas@mauriserateget.com</d:Email>
</m:properties>
</content>
</entry>
...
<link rel="next" href="http://localhost:59389/ContactOData.svc/Contacts?$skiptoken=20" />
</feed>
Notice that it follows the standard Atom format. Every entry has a clear location including where to go to post updates (“edit”). The full data set includes 20 entries and then specifies a link to grab the next page.
Adding this to the Silverlight client is easy. You can add a service reference, discover it in the current solution and the client will be wired for you automatically. Using a DataGrid that auto-generates the columns, I can write the following code behind:
public partial class ODataClient
{
private readonly DataServiceCollection<Contact> _contacts;
private readonly ContactsEntities _context;
private DataServiceQueryContinuation<Contact> _nextPage;
public ODataClient()
{
InitializeComponent();
_context = new ContactsEntities(new Uri("../ContactOData.svc", UriKind.Relative));
_contacts = new DataServiceCollection<Contact>();
_contacts.LoadCompleted += ContactsLoadCompleted;
var query = _context.Contacts.IncludeTotalCount();
_contacts.LoadAsync(query);
}
void ContactsLoadCompleted(object sender, LoadCompletedEventArgs e)
{
_nextPage = _contacts.Continuation;
if (_nextPage == null)
{
NextPage.IsEnabled = false;
}
TotalCount.Text = e.QueryOperationResponse.TotalCount.ToString();
Count.Text = _contacts.Count.ToString();
dgContacts.ItemsSource = _contacts;
dgContacts.UpdateLayout();
}
void Button_Click(object sender, RoutedEventArgs e)
{
_contacts.LoadNextPartialSetAsync();
}
}
The fields hold references to the service. It is instantiated with a relative path to the end point. The query is extended to include a total count of records so it can be used to calculate page sizes, and the link to the next page is retrieved and stored for the continuation. When the user clicks the button to load the next block of records, the continuation is called to fetch the next page. The grid and button look like this:
The example is a quick-and-dirty way to parse the OData stream but can be extended to include a proper paging control (instead of simply expanding the grid) as well as edit and update functionality. Now I’ll show you how to do the same thing using WCF RIA. The obvious advantage with WCF RIA is that the code projection removes most of the manual steps you need to take.
The domain service for WCF RIA simply maps operations like queries to the corresponding LINQ-to-Entities commands. This example is read-only so the full implementation looks like this:
[EnableClientAccess]
public class ContactService : LinqToEntitiesDomainService<ContactsEntities>
{
public IQueryable<Contact> GetContacts()
{
return ObjectContext.Contacts.OrderBy(c => c.Id);
}
}
The service derives from the context for the contact database and the query simply orders the items to allow paging (the result set must be deterministic for paging to work). That’s it on the server side. A metadata class is also generated that you can use to apply data annotations to specify column names, validations, etc.
The client automatically has the WCF RIA classes “projected” which is a fancy way of saying the code is generated for the client. In fact, WCF RIA handles so much plubming that the WCF RIA client doesn’t have to have a single line of code-behind. Instead, you can drop in a domain data source:
<riaControls:DomainDataSource
AutoLoad="true"
d_DesignData="{d:DesignInstance Web:Contact, CreateList=true}"
Height="0"
Name="contactDataSource"
QueryName="GetContacts"
Width="0"
LoadSize="60"
PageSize="20">
<riaControls:DomainDataSource.DomainContext>
<Web:ContactContext/>
</riaControls:DomainDataSource.DomainContext>
</riaControls:DomainDataSource>
By convention, ContactService is renamed to ContactContext on the client. The domain data service uses context as its data source. It is given some design-time data to generate the grid properly, the query to get the list of contacts is specified along with how many records to pre-fetch and how many to show on a page. A DataGrid simply binds to this as the data source along with a DataPager:
<sdk:DataGrid AutoGenerateColumns="True"
ItemsSource="{Binding ElementName=contactDataSource, Path=Data}"/>
<sdk:DataPager
Source="{Binding ElementName=contactDataSource, Path=Data}"/>
And that is it! It will handle computing total records, managing pages, and generating the grid. The result looks like this:
That provides what I would call the ultimate rapid development experience. It can literally take just five minutes to create the Entity Framework model, map the domain service, then drop the domain data source and grid controls on the client to have a fully functional application. Of course, as a developer you may want more control over how the application works and perhaps need to make sure this fits within your existing patterns. The most popular pattern for Silverlight development is Model-View-ViewModel (MVVM) so here is a quick view model to make it work:
Instead of relying on WCF RIA you can abstract the data access layer using a pattern such as repository. This isn’t a full implementation but the simple interface looks like this:
public interface IRepository
{
void ProcessPage(int page, int pageSize,
Action<IEnumerable<Contact>> callback);
int GetTotalPages(int pageSize);
}
Now you can use a mock to test access to the repository and even swap layers if or when it is necessary. Here is an implementation that works directly with WCF RIA:
public class Repository : IRepository
{
private int _totalCount;
private readonly ContactContext _contactContext = new ContactContext();
public Repository()
{
var query = (
from c
in _contactContext.GetContactsQuery()
select c).Take(1);
query.IncludeTotalCount = true;
_contactContext.Load(
query,
callback => { _totalCount = callback.TotalEntityCount; }, null);
}
public void ProcessPage(int page, int pageSize,
Action<IEnumerable<Contact>> callback)
{
var take = pageSize;
var skip = pageSize*(page - 1);
var query = (from c in _contactContext.GetContactsQuery()
select c).Skip(skip).Take(take);
query.IncludeTotalCount = true;
_contactContext.Load(
query,
cb =>
{
_totalCount = cb.TotalEntityCount;
callback(cb.Entities);
}, null);
}
public int GetTotalPages(int pageSize)
{
return (_totalCount/pageSize) + 1;
}
}
Note when the repository is created, it queries for a single item just to grab the full count for computing the page size. This is updated each subsequent call for a page. The call to grab the page computes how many records to skip and take for a page and then executes the query.
A simple view model can be constructed that uses the repository:
public class ViewModel : INotifyPropertyChanged
{
private List<Contact> _contacts = new List<Contact>();
private readonly IRepository _repository;
public int CurrentPage { get; set; }
public int TotalPages { get; set; }
public IActionCommand NextPage { get; set; }
public IActionCommand PreviousPage { get; set; }
public IEnumerable<Contact> Contacts
{
get
{
if (_contacts.Count == 0)
{
Refresh();
}
return _contacts;
}
set { _contacts = new List<Contact>(value); }
}
}
It exposes current page, total pages, commands to paginate and a list of the current contacts. The constructor sets up the initial conditions and sets a dummy page and page size in the design view:
public ViewModel()
{
Contacts = new List<Contact>();
NextPage = new ActionCommand<object>(obj => GoToNextPage(),
obj => CurrentPage < TotalPages);
PreviousPage = new ActionCommand<object>(obj => GoToPreviousPage(),
obj => CurrentPage > 1);
if (!DesignerProperties.IsInDesignTool)
{
CurrentPage = 1;
_repository = new Repository();
}
else
{
CurrentPage = 2;
TotalPages = 10;
}
}
The Refresh method fetches the current page:
private void Refresh()
{
_repository.ProcessPage(
CurrentPage,
20,
cb =>
{
TotalPages = _repository.GetTotalPages(20);
_contacts = new List<Contact>(cb);
RaiseChanges();
});
}
The commands simply change the current page and call refresh. For example, the command to advance by one page:
private void GoToNextPage()
{
CurrentPage++;
Refresh();
}
Now the view model can be bound to a grid. In this example, the current page and page count are used to construct a very simple paging control. All of the information you need to make a full-blown control is available. The MVVM-based view looks like this:
The ease with which it is possible to navigate a large data set from the client is one of the reasons I believe Silverlight is still a strong player in the Line of Business application space. For a more modern approach, check out this whitepaper about XAML migration strategies. More details and the full source code for this example will be available when my book publishes. As of this writing on November 20, 2011 it is discounted over 40% on Amazon when you pre-order a copy from here. Thanks!
Microsoft Azure and Amazon Web Services (AWS) are two of the most popular cloud platforms.…
Cloud management is difficult to do manually, especially if you work with multiple cloud…
Azure’s scalable infrastructure is often cited as one of the primary reasons why it's the…
https://www.youtube.com/watch?v=wDzCN0d8SeA Watch our "Unlocking the Power of AI in your Software Development Life Cycle (SDLC)"…
FinOps is a strategic approach to managing cloud costs. It combines financial management best practices…
Using Kubernetes with Azure combines the power of Kubernetes container orchestration and the cloud capabilities…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Looks its going to be a great book. Thanks for supporting such important issues like Enterprise products!
Can I download this anywhere? A complete example with MVVM would be nice.
thanks for the work.
Tim
Thanks for sharing.
Howerver, in a way you are not handeling large data sets. You just use paging to only have to download one page at a time. We also have a developer here who thinks that LOB applications are just about seeing the date in pages. It's just a technical solution so that the developer doesn't have to deal with the challanges one is facing when really dealing with large datasets in one go. Paging and virtualisation are all nice techniques in some cases. However in other cases one just wants to manipulate the data in one go.
A user is not going to be able to handle 990,000 records in one go. They may want to have an action available to "update all" but no one can process that much information. A large data set has to be filtered and mined somehow for the end user to comprehend and process that. It may be through roll-up and summary information, through filters and commands - but is there a valid case for actually SHOWING 990,000 records? I've yet to find an application that either (a) does this or (b) does it and is still usable. Again, I believe "never say never" but I'm just struggling with the user case here.
Hello Jeremy,
Few thoughts around the business case of bringing 990,000 at one shot:
1- Sometimes you want the ability to group by column and get summaries per group. As some of those 3rd party controls allow you to do this. So if we have paging, are we still able to group by column or this grouping will be applicable just to the displayed page? What happens if a group consists of multiple pages......
2- Some data grids come with expression editor functinality where a user can add a calculation on a column in the grid. If we are using paging, can we apply calcuation on the whole column or is it going to be on a page by page?
3- If the Grid has filtering capability for each column then are we going to be able apply the filter on the whole data set or just that displayed page?
Obviously there is a performance hit when bringing all records and possibility to time out. I appreciate your feedback.....
Some slip covers are made especially for businesses, schools, athletic teams and other institutions that wish to provide products. These slip covers feature embroidered logos and are usually shaped to fit just over the back of any normal-sized folding chair.
[url=http://www.knicksjerseysmart.com/new-york-knicks-jerseys-amare-stoudemire-jersey-c-20_25.html]Carmelo Anthony Jersey[/url]
Carmelo Anthony Jersey